TL;DR
Use JPA libraries to communicate with Apache Cassandra comparing Achilles, Datastax and Kundera. The last one presents the better processing speeds with lower computational resources consumption.
Source code is available on Github with detailed documentation on how to build and run the tests using Docker.
Goal
With the overwhelming amounts of data being generated in nowadays technological solutions, one of the main challenges is to find the best solutions to properly store, manage and serve huge amounts of data. Apache Cassandra is one of such solutions, which is a NoSQL database designed for large-scale data management with high availability, consistency and performance. When performing millions of operations per day on top of such databases, every millisecond counts with significant impact on overall system behavior.
The main goal of this project is to use different JPA libraries to communicate with Cassandra, comparing usage complexity, processing speeds and resources usage. The following architecture is proposed to achieve the aforementioned goal, which contains the following components and interfaces:
- Cassandra: database for large-scale data management;
- Datastax Native: Java library to communicate with Cassandra;
- Datastax ORM: JPA library to communicate with Cassandra;
- Kundera: JPA library to communicate with Cassandra;
- Achilles: JPA library to communicate with Cassandra.
 Figure: Illustration of the implementation architecture of Cassandra and JPA clients.
Figure: Illustration of the implementation architecture of Cassandra and JPA clients.
The architecture is implemented using following technologies:
- Jave 8: main programming language for experiment;
- Maven: dependency management and package building;
- Docker: components containerization, orchestration and setup;
- Docker Compose: simplify running multi-container solutions with dependencies.
Apache Cassandra
Apache Cassandra is an open-source and distributed column-based database, designed for large-scale applications and to handle large amounts of data with high availability with no single point of failure. It was initially developed at Facebook and is currently part of the Apache Software Foundation. Nowadays, Apache Cassandra is one of the most used NoSQL databases, as we can see in the Figure below:
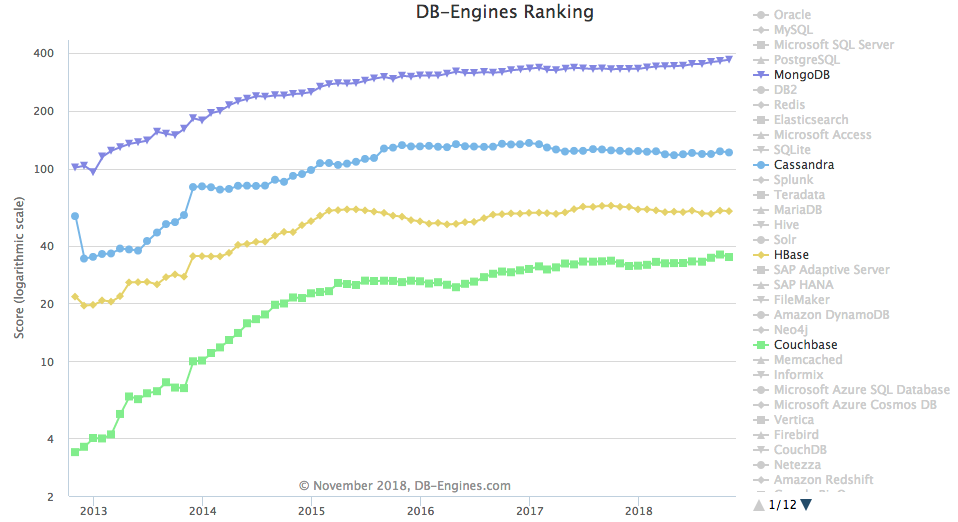 Figure: Popularity of several NoSQL databases from DB-Engines.
Figure: Popularity of several NoSQL databases from DB-Engines.
When comparing Cassandra with other NoSQL databases, various studies already present a detailed evaluation and comparison, such as: End Point, Altoros, and Çankaya University. Overall, Cassandra presents top results when used with large amounts of data and with multiple nodes, achieving high throughput with low latency. Thus, Cassandra might be recommended when:
- Run on more than one server node, specially with a geographically distributed cluster;
- Data can be partitioned via a key, which allows the database to be spread across multiple nodes;
- Writes exceed reads by a large margin;
- Read access is performed by a known primary key;
- Data is rarely updated;
- There is no need to perform join or aggregate operations (e.g., sum, min, or max), since they must be pre-computed and stored.
Many companies are effectively using Cassandra as the core data storage and management solution, such as CapitalOne, Coursera, eBay, Hulu and NASA. Such examples show that Cassandra can be used with different types of data and targeting different purposes, such as financial, health, entertainment, web analytics and IoT.
Apache Cassandra is available in major cloud providers, such as Amazon AWS, Microsoft Azure and Google Cloud. However, both Amazon and Microsoft provide their own NoSQL database implementations (DynamoDB and CosmosDB), with support for Cassandra APIs and migration. Other companies provide enterprise support for on-premises or cloud installation and maintenance, such as Datastax and Bitnami.
JPA libraries for Cassandra
The official Cassandra documentation page presents a comprehensive list of available libraries to communicate with Cassandra using Java. A brief analysis shows that only some projects are active and have significant community support:
- Achilles: active project with small community;
- Astyanax: deprecated and is no longer supported;
- Casser: very small community and is not clear if project is still active;
- Datastax: active project with large community and enterprise interest;
- Kundera: active project with large community;
- PlayORM: specific for Play Framework and project does not look active.
Based on such analysis, Achilles, Datastax and Kundera are the JPA libraries that will be considered during this analysis. To have a point of comparison, both Datastax Native and Datastax ORM implementations will be used.
How to compare JPA libraries?
In order to have a fair performance and resources usage comparison of the several JPA libraries for Cassandra, it is important to consider and analyse several questions in detail, such as:
- Which database operations should be executed and compared?
- What type of data should be considered?
- What is the data complexity?
- What are the relevant performance indicators?
- How to measure and collect the performance indicators?
- How to collect consistent results without interferences and outliers?
Taking the previous topics into consideration, the following testing guidelines were defined:
- Operation types: write, read, update and delete;
- Data type: single table with simple fields and without relations;
- Data singularity: all operations should be performed with unique data values to avoid caching;
- Performance measurement: elapsed time to perform each operation;
- Resources usage measurement: CPU and RAM usage of client and server applications;
- Repetition factor: all tests should be repeated several times to collect average values instead of results from single executions.
A simplistic approach will be followed for the data definition. The following Figure illustrates the User class that will be used during the tests, which contains only four textual attributes (unique identifier, first name, last name and city). In summary, everytime an operation is performed, an instance of the User class is being written, read, updated or deleted on Cassandra.
 Figure: Illustration of the simple
Figure: Illustration of the simple User class and respective attributes.
The following pseudocode presents the algorithm applied to collect the processing times for each library and operation types, using a set of users with different attributes. For each library and test cycle, each operation type (write, read, update and delete) will be executed \(O\) times (TOTAL_OPERATIONS), which is repeated \(R\) times (TOTAL_REPETITIONS) to calculate the average of total processing times. If multiple cycles are defined, the previous process is repeated \(C\) times (TOTAL_CYCLES) to collect average values of all repetitions. In the end, average times of all cycles and repetitions are collected per library and operation type. That way, all tasks are repeated to make sure external interferences have no impact on compared processing times.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
FOR EACH library in [datastax_native, datastax_orm, kundera, achilles]
FOR EACH cycle in TOTAL_CYCLES (C)
SET users of size TOTAL_REPETITIONS*TOTAL_OPERATIONS
FOR EACH operation type in [write, read, update, delete]
FOR EACH repetition in TOTAL_REPETITIONS (R)
FOR EACH operation in TOTAL_OPERATIONS (O)
GET unique user from users
CALL operation with unique user instance
GET operation processing time
END FOR
GET total time of all operations
END FOR
GET average of repeated total times
END FOR
GET average times per operation type
END FOR
GET average times per library and operation type
END FOR
Pseudocode: Algorithm defined to perform JPA libraries tests.
While executing the operations in the Java application, CPU and RAM resources usage will be collected on both client and server applications. By doing this we are able to evaluate if there is any significant impact of each JPA library on the Java application and Cassandra server resources usage.
If you would like to check the results right away, you can jump to the Results section below.
Implementation
The Java application implementation was performed to minimize code replication as much as possible. However, different User classes are required to provide the specific Java annotations. Thus, the following Figure illustrates how the User interface is used to make sure different User classes implement the required methods.
 Figure: Illustration of the
Figure: Illustration of the User implementation.
To minimize complexity and to make sure that the different tests have the same core behavior, the Run abstract class implements methods to run write, read, update and delete tests using the configured number of operations, repetitions and cycles. That way, specific run classes only have to implement core methods to perform atomic operations using each JPA library. The following Figure illustrates such implementation details.
 Figure: Illustration of the
Figure: Illustration of the Run implementation.
Finally, the main application just needs to take advantage of the run() methods to execute all the designed tests, as presented in the following Figure.
 Figure: Illustration of the
Figure: Illustration of the Main implementation.
Cassandra Server
Before starting with implementation details, it is crucial to have a Cassandra server running, towards developing and testing the code. The following Docker Compose YML file is provided to run the Cassandra server with an attached network.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
version: '3.6'
networks:
bridge:
driver: bridge
services:
cassandra:
image: cassandra:3.11
environment:
CASSANDRA_START_RPC: "true"
CASSANDRA_CLUSTER_NAME: cassandra
networks:
bridge:
aliases:
- cassandra
Code: docker-compose.yml file for running Cassandra.
Unfortunately it was not possible to find any good web-based tool to access and manage Cassandra. In order to validate if operations were performed properly, a RazorSQL trial license was used instead. Let me know if you know any good web-based alternative ![]() .
.
Finally, the Cassandra server can be started using the docker compose tool as following:
1
docker-compose up -d
Datastax Native
To use Datastax Native, the core Java dependency is required and should be defined in the project POM file.
1
2
3
4
5
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-core</artifactId>
<version>3.6.0</version>
</dependency>
Code: Maven dependency for Datastax Native implementation.
The code snippet below exemplifies how Datastax Native QueryBuilder can be used to connect, write, read, update and delete User data to/from Cassandra.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// Connect
Cluster cluster = Cluster.builder()
.addContactPoint(Commons.EXAMPLE_CASSANDRA_HOST)
.build();
Session session = cluster.connect();
// Write
Insert insert = QueryBuilder
.insertInto("example", "user")
.value("id", uuid)
.value("first_name", "John")
.value("last_name", "Smith")
.value("city", "London");
session.execute(insert);
// Read
Select.Where select = QueryBuilder
.select("id", "first_name", "last_name", "city")
.from("example", "user")
.where(QueryBuilder.eq("id", uuid));
ResultSet rs = session.execute(select);
// Update
Update.Where update = QueryBuilder
.update("example", "user")
.with(QueryBuilder.set("first_name", "___u"))
.and(QueryBuilder.set("last_name", "___u"))
.and(QueryBuilder.set("city", "___u"))
.where(QueryBuilder.eq("id", uuid));
ResultSet rs = session.execute(update);
// Delete
Delete.Where delete = QueryBuilder
.delete()
.from("example", "user")
.where(QueryBuilder.eq("id", uuid));
session.execute(delete);
Code: Example code to perform connect, write, read, update and delete operations using Datastax Native.
Datastax ORM
In addition to the core Datastax dependency, the mapping dependency is also required to support the ORM implementation:
1
2
3
4
5
<dependency>
<groupId>com.datastax.cassandra</groupId>
<artifactId>cassandra-driver-mapping</artifactId>
<version>3.5.1</version>
</dependency>
Code: Maven dependency for Datastax ORM implementation.
The UserDatastax class is defined using the Java annotations provided by Datastax, which allow to define table and column characteristics, such as name and primary key.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@Table(keyspace = "example", name = "user",
readConsistency = "QUORUM",
writeConsistency = "QUORUM",
caseSensitiveKeyspace = false,
caseSensitiveTable = false)
public class UserDatastax implements User {
@Column(name = "id")
@PartitionKey
private UUID id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
@Column(name = "city")
private String city;
...
}
Code: Datastax User implementation.
The code snippet below shows how simple is to perform connect, write, read, update and delete operations using Datastax ORM.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// Connect
Cluster cluster = Cluster.builder()
.addContactPoint(Commons.EXAMPLE_CASSANDRA_HOST)
.build();
Session session = cluster.connect();
// Write
UserDatastax user = new UserDatastax(uuid, "John", "Smith", "London");
mapper.save(user);
// Read
UserDatastax user = (UserDatastax) mapper.get(uuid);
// Update
UserDatastax user = users.get(uuid);
user.setFirstName(user.getFirstName() + "___u");
user.setLastName(user.getLastName() + "___u");
user.setCity(user.getCity() + "___u");
mapper.save(user);
// Delete
UserDatastax user = users.get(uuid);
mapper.delete(user);
Code: Example code to perform connect, write, read, update and delete operations using Datastax ORM.
Kundera
The following Java dependencies are added to use Kundera:
1
2
3
4
5
6
7
8
9
10
<dependency>
<groupId>com.impetus.kundera.core</groupId>
<artifactId>kundera-core</artifactId>
<version>3.13</version>
</dependency>
<dependency>
<groupId>com.impetus.kundera.client</groupId>
<artifactId>kundera-cassandra</artifactId>
<version>3.13</version>
</dependency>
Code: Maven dependencies for Kundera implementation.
Persistence configuration of Kundera is performed using the persistence.xml file, in order to specify how connectivity is performed to Cassandra and identify the classes that should be mapped. In order to automatically create the database, change the kundera.ddl.auto.prepare property from update to create.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<persistence xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="cassandra_pu">
<provider>com.impetus.kundera.KunderaPersistence</provider>
<class>org.davidcampos.cassandra.kundera.UserKundera</class>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
<properties>
<property name="kundera.nodes" value="cassandra"/>
<property name="kundera.port" value="9160"/>
<property name="kundera.keyspace" value="example"/>
<property name="kundera.dialect" value="cassandra"/>
<property name="kundera.ddl.auto.prepare" value="update"/>
<property name="kundera.client.lookup.class"
value="com.impetus.client.cassandra.thrift.ThriftClientFactory"/>
</properties>
</persistence-unit>
</persistence>
Code: Kundera persistence configuration.
Adding Cassandra connectivity configurations to persistence.xml reduces the required properties in the UserKundera class. Special attention to the schema property that makes the link with the persistence-unit previously defined in the XML file.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
@Entity
@Table(name = "user", schema = "example@cassandra_pu")
public class UserKundera implements User {
@Id
@Column(name = "id")
private UUID id;
@Column(name = "first_name")
private String firstName;
@Column(name = "last_name")
private String lastName;
@Column(name = "city")
private String city;
...
}
Code: Kundera User implementation.
The following code snippet presents how Kundera can be used to perform connect, write, read, update and delete operations on Cassandra.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// Connect
Map<String, String> props = new HashMap<>();
props.put(CassandraConstants.CQL_VERSION, CassandraConstants.CQL_VERSION_3_0);
EntityManagerFactory emf = Persistence.createEntityManagerFactory("cassandra_pu", props);
EntityManager em = emf.createEntityManager();
// Write
UserKundera user = new UserKundera(uuid, "John", "Smith", "London");
em.persist(user);
// Read
UserKundera user = em.find(UserKundera.class, uuid);
// Update
UserKundera user = users.get(uuid);
user.setFirstName(user.getFirstName() + "___u");
user.setLastName(user.getLastName() + "___u");
user.setCity(user.getCity() + "___u");
em.merge(user);
// Delete
UserKundera user = users.get(uuid);
em.remove(user);
Code: Example code to perform connect, write, read, update and delete operations using Kundera.
By default Kundera provides a considerable amount of logging information, which can be minimized by adding the following logback.xml file to the resources folder.
1
2
3
<configuration>
<root level="ERROR"></root>
</configuration>
Achilles
Achilles requires the following Java dependency to be added to the POM file:
1
2
3
4
5
<dependency>
<groupId>info.archinnov</groupId>
<artifactId>achilles-core</artifactId>
<version>6.0.0</version>
</dependency>
Code: Maven dependency for Achilles implementation.
As presented below, the UserAchilles class is defined with the respective Java annotations.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@Table(table = "user")
public class UserAchilles implements User {
@Column(value = "id")
@PartitionKey
private UUID id;
@Column(value = "first_name")
private String firstName;
@Column(value = "last_name")
private String lastName;
@Column(value = "city")
private String city;
...
}
Code: Achilles User implementation.
After the definition of the entity classes, Achilles requires to build the project to automatically generate the manager classes that allow to interact with Cassandra. If any change is performed in any entity class, the project needs to be built again to generate the manager classes again. To enable source code auto-complete of such classes on IntelliJ IDEA, the generated classes need to be added as sources of the project, as we can see in the Figure below.
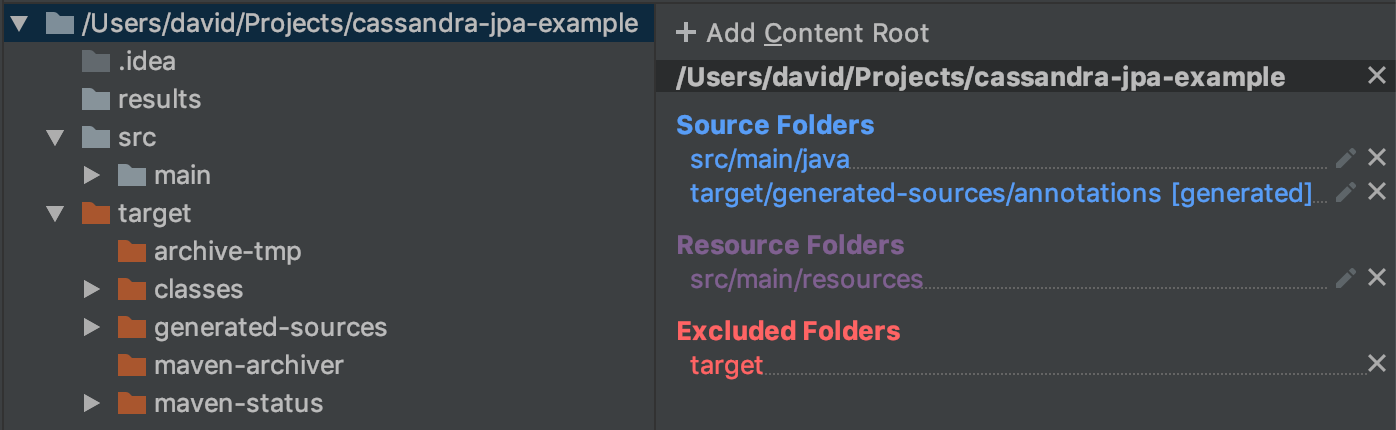 Figure: Project sources configuration on IntelliJ IDEA.
Figure: Project sources configuration on IntelliJ IDEA.
The following code snippet presents how to perform connect, write, read, update and delete operations using the UserAchilles_Manager class generated by Achilles.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
// Connect
Cluster cluster = Cluster.builder()
.addContactPoint(Commons.EXAMPLE_CASSANDRA_HOST)
.build();
Session session = cluster.connect();
ManagerFactory managerFactory = ManagerFactoryBuilder
.builder(cluster)
.withDefaultKeyspaceName("example")
.doForceSchemaCreation(true)
.build();
UserAchilles_Manager manager = managerFactory.forUserAchilles();
// Write
UserAchilles user = new UserAchilles(uuid, "John", "Smith", "London");
manager.crud().insert(user).execute();
// Read
UserAchilles user = manager.crud().findById(uuid).get();
// Update
UserAchilles user = users.get(uuid);
user.setFirstName(user.getFirstName() + "___u");
user.setLastName(user.getLastName() + "___u");
user.setCity(user.getCity() + "___u");
manager.crud().update(user).execute();
// Delete
UserAchilles user = users.get(uuid);
manager.crud().delete(user).execute();
Code: Example code to perform connect, write, read, update and delete operations using Achilles.
Elapsed time measurement
The measurement of the elapsed time is performed to check the execution of the atomic operation only. This means that the time required to create or get User objects will not be considered. In the following code example we can check that a Stopwatch is used to measure the elapsed time of the persist operation only.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// Get UUID
UUID uuid = Commons.uuids.get(repetition * Commons.OPERATIONS + i);
// Create user
UserKundera user = new UserKundera(
uuid,
"John" + i,
"Smith" + i,
"London" + i
);
users.put(uuid, user);
// Store user
Commons.resumeOrStartStopWatch(stopwatch);
em.persist(user);
stopwatch.suspend();
Code: Example code to measure the operation elapsed time.
Main
To get everything together, the Main application is created to run the tests for each JPA library, considering the configurations provided in environment variables.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class Main {
public static void main(final String... args) throws InterruptedException {
RunDatastaxNative runDatastaxNative = new RunDatastaxNative();
runDatastaxNative.run();
RunDatastax runDatastax = new RunDatastax();
runDatastax.run();
RunKundera runKundera = new RunKundera();
runKundera.run();
RunAchilles runAchilles = new RunAchilles();
runAchilles.run();
}
}
Code: Main program to run the tests for each JPA library.
Configurations
The following configurations are required to connect with the Apache Cassandra server and configure the tests properly:
- “EXAMPLE_CASSANDRA_HOST” and “EXAMPLE_CASSANDRA_PORT”: Cassandra host and port;
- “EXAMPLE_OPERATIONS”: number of operations to run;
- “EXAMPLE_REPETITIONS”: number of times to repeat operations execution and average values;
- “EXAMPLE_CYCLES”: number of times to repeat tests execution and average values.
Such configurations will be loaded from environment variables using the Commons class, which assumes default values if no environment variables are defined. Moreover, unique identifiers are also generated to perform each operation using an UUID that was never used before, creating EXAMPLE_OPERATIONS*EXAMPLE_REPETITIONS unique identifiers.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public final static int OPERATIONS = System.getenv("EXAMPLE_OPERATIONS") != null ?
Integer.parseInt(System.getenv("EXAMPLE_OPERATIONS")) : 1000;
public final static int REPETITIONS = System.getenv("EXAMPLE_REPETITIONS") != null ?
Integer.parseInt(System.getenv("EXAMPLE_REPETITIONS")) : 5;
public final static int CYCLES = System.getenv("EXAMPLE_CYCLES") != null ?
Integer.parseInt(System.getenv("EXAMPLE_CYCLES")) : 5;
public static List<UUID> uuids = generateUUIDs();
public final static String EXAMPLE_CASSANDRA_HOST = System.getenv("EXAMPLE_CASSANDRA_HOST") != null ?
System.getenv("EXAMPLE_CASSANDRA_HOST") : "cassandra";
public final static String EXAMPLE_CASSANDRA_PORT = System.getenv("EXAMPLE_CASSANDRA_PORT") != null ?
System.getenv("EXAMPLE_CASSANDRA_PORT") : "9160";
Code: Commons class to load project configurations from environment variables.
Packaging
To build fat JAR file with all dependencies included, the Maven Assembly Plugin was used with the following configurations:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>org.davidcampos.cassandra.main.Main</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
Since several classes have the @Table Java annotation in the same JAR package, Kundera will consider all annotated classes as persistence entities, which will cause an error similar to:
1
2
3
4
5
6
7
8
9
10
Exception in thread "main" com.impetus.kundera.loader.MetamodelLoaderException: Error while retrieving and storing entity metadata
at com.impetus.kundera.configure.MetamodelConfiguration.loadEntityMetadata(MetamodelConfiguration.java:238)
at com.impetus.kundera.configure.MetamodelConfiguration.configure(MetamodelConfiguration.java:112)
at com.impetus.kundera.persistence.EntityManagerFactoryImpl.configure(EntityManagerFactoryImpl.java:158)
at com.impetus.kundera.persistence.EntityManagerFactoryImpl.<init>(EntityManagerFactoryImpl.java:135)
at com.impetus.kundera.KunderaPersistence.createEntityManagerFactory(KunderaPersistence.java:85)
at javax.persistence.Persistence.createEntityManagerFactory(Persistence.java:79)
at org.davidcampos.cassandra.kundera.KunderaExample.runWrites(KunderaExample.java:37)
at org.davidcampos.cassandra.kundera.KunderaExample.main(KunderaExample.java:21)
at org.davidcampos.cassandra.Main.main(Main.java:12)
To fix the error, please make sure Kundera excludes non-expected entity classes, adding the following configuration to the persistence.xml file:
1
<exclude-unlisted-classes>true</exclude-unlisted-classes>
Finally, to build the fat JAR, please run mvn clean package in the project folder, which stores the resulting JAR cassandra-jpa-example-1.0-SNAPSHOT-jar-with-dependencies.jar in the target folder.
Docker image
To build the Docker Image for the Java application, the following Dockerfile was built using the OpenJDK image as baseline:
1
2
3
4
5
6
7
8
9
10
11
12
13
FROM openjdk:8u151-jdk-alpine3.7
MAINTAINER David Campos (david.marques.campos@gmail.com)
# Install Bash
RUN apk add --no-cache bash
# Copy resources
WORKDIR /
COPY wait-for-it.sh wait-for-it.sh
COPY target/cassandra-jpa-example-1.0-SNAPSHOT-jar-with-dependencies.jar cassandra-jpa-example.jar
# Wait for Cassandra and Kafka to be available and run application
CMD ./wait-for-it.sh -s -t 180 $EXAMPLE_CASSANDRA_HOST:$EXAMPLE_CASSANDRA_PORT -- java -Xmx512m -jar cassandra-jpa-example.jar
Code: Dockerfile to build Java application Docker image.
wait-for-it.sh is used to check if a Cassandra host and port is available and only run the Java application when connectivity is established. To build the docker image, run the following command in the project folder:
1
docker build -t cassandra-jpa-example .
Docker compose
To create the container to run the Java application with the tests, the previous Docker Compose YML file should be extended adding the application configurations. The environment variables that provide the Cassandra and Test configurations are also provided.
1
2
3
4
5
6
7
8
9
10
11
12
java:
image: cassandra-jpa-example
depends_on:
- cassandra
environment:
EXAMPLE_CASSANDRA_HOST: "cassandra"
EXAMPLE_CASSANDRA_PORT: "9160"
EXAMPLE_REQUEST_WAIT: 0
EXAMPLE_ITERATIONS: 10000
EXAMPLE_REPETITIONS: 3
networks:
- bridge
Code: Part of docker-compose.yml file for running Java application.
CPU and RAM usage
To collect resources usage of Cassandra and Java application separately, we decided to take advantage of the docker stats utility, which provides detailed RAM and CPU usage of a target container and also allows to customize the output data format. The following script allows to continuously collect Cassandra’s container resources usage and store the results in the TSV file stats-cassandra.tsv.
1
2
#!/usr/bin/env bash
while true; do docker stats --no-stream cassandra-jpa-example_cassandra_1 --format "\t{{.MemUsage}}\t{{.MemPerc}}\t{{.CPUPerc}}" | ts >> stats-cassandra.tsv; done
Code: Script to collect RAM and CPU usage of a docker container.
Run
Now that everything is in place, it is time to start the containers using the docker-compose tool, passing the -d argument to detach and run the containers in the background:
1
docker-compose up -d
Such execution will provide detailed feedback regarding the success of creating and running each container and network:
1
2
3
Creating network "cassandra-jpa-example_bridge" with driver "bridge"
Creating cassandra-jpa-example_cassandra_1 ... done
Creating cassandra-jpa-example_java_1 ... done
In order to check if everything is working properly, we can take advantage of the docker logs tool to analyse the output being generated on each container.
1
docker logs kafka-spark-flink-example_kafka-producer_1 -f
Output should be similar to the following example:
1
2
3
4
5
6
wait-for-it.sh: waiting 180 seconds for cassandra:9160
wait-for-it.sh: cassandra:9160 is available after 17 seconds
17:19:24.002 [main] INFO org.davidcampos.cassandra.datastax_native.RunDatastaxNative - WRITE 3 38102 16434 10255 12700.666666666666
17:20:02.617 [main] INFO org.davidcampos.cassandra.datastax_native.RunDatastaxNative - READ 3 35910 14873 10247 11970.0
17:20:35.775 [main] INFO org.davidcampos.cassandra.datastax_native.RunDatastaxNative - UPDATE 3 30508 11592 9240 10169.333333333334
17:21:08.828 [main] INFO org.davidcampos.cassandra.datastax_native.RunDatastaxNative - DELETE 3 30453 10565 9673 10151.0
In parallel run docker-stats-cassandra.sh and docker-stats-java.sh scripts to collect results of CPU and RAM usage on Cassandra and Java application containers. Such measurements are stored in TSV files with the following format:
1
2
3
4
5
6
Dec 15 16:53:46 1.06GiB / 1.952GiB 54.29% 138.51%
Dec 15 16:53:48 1.087GiB / 1.952GiB 55.71% 160.26%
Dec 15 16:53:50 1.141GiB / 1.952GiB 58.44% 218.72%
Dec 15 16:53:52 1.137GiB / 1.952GiB 58.25% 180.90%
Dec 15 16:53:54 1.137GiB / 1.952GiB 58.25% 6.11%
Dec 15 16:53:56 1.117GiB / 1.952GiB 57.23% 4.69%
Results
Please keep in mind that the results collected are highly related with the pre-conditions previously described, namely:
- Elapsed time measured considering atomic operations only;
- Single thread application to perform operations;
- Tests executed on macOS using a MacBook Pro with 4 cores @ 2,3GHz and 16GB RAM;
- Cassandra and Java Application running on top of Docker;
- CPU and RAM usage collected using
docker stats.
The results were collected with the following configurations:
- Number of operations: 1000, 5000 and 10000;
- Number of repetitions: 3;
- Number of cycles: 3.
The Figure below presents the average of the measured times for the several libraries and operation types. Overall, delete operations are the fastest ones, followed by the write tasks. As expected by Cassandra architecture and functionality, read operations are the ones that take longer execution time. When comparing the used JPA libraries, Kundera presents the fastest performance times in write, read, update and delete operation types. On the other hand, Achilles presents the worst results. Comparing the best with the worst library, for 10K operations we have an average difference of 3.2 seconds. If we extrapolate for 10M operations, this execution time difference can reach almost 1 hour. In average, Kundera performance is 28% better than Achilles, 19% better than Datastax, and 24% better than Native. It is quite interesting to see that Datastax ORM presents similar or better time measurements than Datastax Native. Keep in mind that the low complexity of the User data is not adding significant complexity on top of native and ORM solutions.
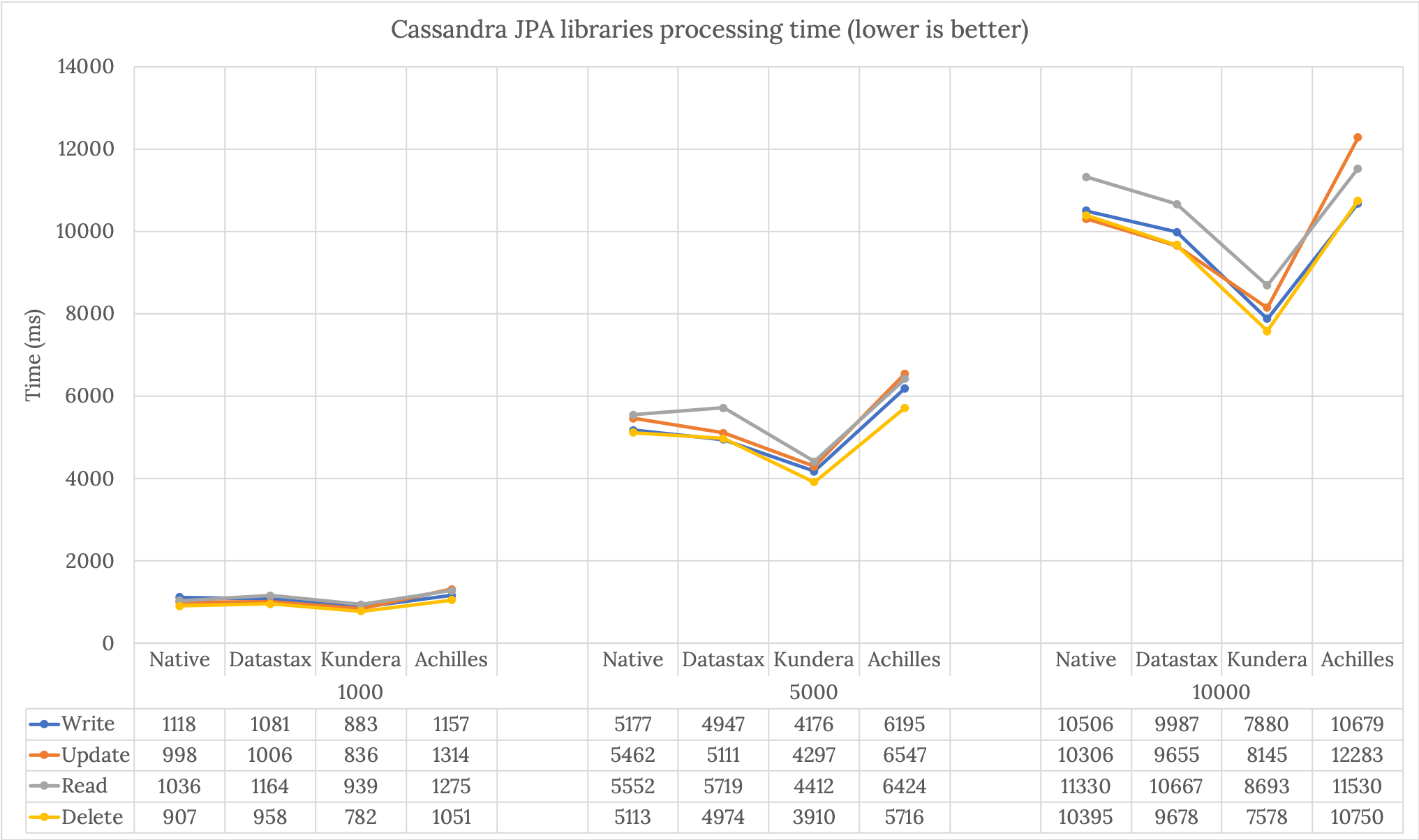 Figure: Comparison of Cassandra JPA libraries processing time for the different operation types.
Figure: Comparison of Cassandra JPA libraries processing time for the different operation types.
Jumping into the resources usage analysis, the Figure below presents CPU and RAM consumption of the Java application and Cassandra while performing the tests. Overall, Kundera presents significant lower CPU usages on both Cassandra and Java application. Regarding RAM, there is no significant difference or impact on Cassandra when all JPA libraries are being used. However, Kundera and Achilles seem to use more RAM than Datastax libraries. For instance, on the 10K operations test, Kundera presents up to 78% less CPU usage on Cassandra, and up to 41% less CPU consumption on Java application. Regarding RAM usage, Kundera and Achilles use more 7% of RAM than Datastax libraries. Such differences might related with the fact that Kundera holds operations on RAM before submitting them to Cassandra, which has a minor impact on RAM but a very significant impact on low CPU consumption both on client and server applications. However, it is still open to clarify if a higher complexity on the stored data will have a higher impact on RAM usage.
 Figure: Comparison of Cassandra JPA libraries resources usage.
Figure: Comparison of Cassandra JPA libraries resources usage.
Conclusion
In conclusion, Kundera presents up to 28% faster performance results with significant lower CPU impact on both client application and Cassandra server. Such interesting results are significant and should be considered while designing your next Cassandra and Java project, in order to reduce resources usage and increase processing throughput. Nevertheless, do not forget to evaluate the behavior of Kundera with your specific data and entities characteristics, requirements and complexity.

Please tell me if you had different results using this or other JPA libraries. Your comments, suggestions and contributions are more than welcome.
Happy new and techy 2019! ![]()
![]()
Comments