TL;DR
Sample project taking advantage of Kafka messages streaming communication platform using:
- 1 data producer sending random numbers in textual format;
- 3 different data consumers using Kafka, Spark and Flink to count word occurrences.
Source code is available on Github with detailed documentation on how to build and run the different software components using Docker.
Goal
The main goal of this sample project is to mimic the streaming communication of nowadays large-scale solutions. An infrastructure is required to enable communication between components generating data sent to a centralized infrastructure. Such data is later consumed by other components with different purposes. The “Hello World” example project of such solutions is the Word Count problem, were producers send words to a central back-end and consumers count occurrences of each word. The following actors are involved:
- Producer sends words in textual format to message broker;
- Message broker receives messages and serves them to registered consumers;
- Consumers process messages and count occurrences of each word.
The following architecture is proposed, which contains the following components:
- Producer: send words to message broker;
- Zookeeper: service for centralized configuration and synchronization of distributed services. In this case it is required to install and configure Kafka;
- Kafka: message broker to receive messages from producer and propagate them to consumers
- Kafka Consumer: count word occurrences using Kafka;
- Spark Consumer: count work occurrences using Spark;
- Flink Consumer: count work occurrences using Flink.
 Figure: Illustration of the implementation architecture of the example project.
Figure: Illustration of the implementation architecture of the example project.
Such infrastructure will run on top of Docker, which simplifies the orchestration and setup processes. If we would like to scale-up the example, we can deploy it in a large-scale Docker-based orchestration platform, such as Docker Swarm and Kubernetes. Additionally, the following technologies are also used:
- Java 8 as main programming language for producer and consumers. Actually tried to use Java 10 first, but had several problems with Spark and Flink Scala versions;
- Maven for producer and consumers dependency management and build purposes;
- Docker Compose to simplify the process of running multi-container solutions with dependencies.
Kafka
Kafka is becoming the de-facto standard messaging platform, enabling large-scale communication between software components producing and consuming streams of data for different purposes. It was originally built at LinkedIn and is currently part of the Apache Software Foundation. The following Figure illustrates the architecture of solutions using Kafka, with multiple components generating data that is consumed by different consumers for different purposes, making Kafka the communication bridge between them.
 Figure: Illustration of Kafka capabilities as a message broker between heterogeneous producers and consumers. Source https://kafka.apache.org.
Figure: Illustration of Kafka capabilities as a message broker between heterogeneous producers and consumers. Source https://kafka.apache.org.
Hundreds of companies already take advantage of Kafka to provide their services, such as Oracle, LinkedIn, Mozilla and Netflix. As a result, it is being used in many different real-life use cases for different purposes, such as messaging, website activity tracking, metrics collection, logs aggregation, stream processing and event sourcing. For instance, in the IoT context, thousands of devices can send streams of operational data to Kafka, which might be processed and stored for many different purposes, such as improved maintenance, enhanced support and functionality optimization. Taking advantage of streaming enables reacting on real-time to relevant changes on connected devices.
Kafka anatomy in 1 minute
To better understand how Kafka works, it is important to understand its main concepts:
- Record: consists of a key, a value and a timestamp;
- Topic: category of records;
- Partition: subset of records of a topic that can reside in different brokers;
- Broker: service in a node with partitions that allows consumers and producers to access the records of a topic;
- Producer: service that puts records into a topic;
- Consumer: service that reads records from a topic;
- Consumer group: set of consumers sharing a common identifier, making sure that all partitions from a topic are read by a consumer group without consumers overlap.
The figure below illustrates the relation between the aforementioned Kafka concepts. In summary, messages that are sent to Kafka are organized into topics. Thus, a producer sends messages to a specific topic and a consumer reads messages from that topic. Each topic is divided into partitions, that can reside in different nodes and enable multiple consumers to read from a topic in parallel. Consumers are organized in consumer groups to make sure that partitions from a topic are consumed at least once, also making sure that each partition is only consumed by a single consumer from the group. Considering the example illustrated in the figure, since Group A has two consumers, each consumer reads records from two different partitions. On the other hand, since Group B has four consumers, each consumer reads records from a single partition only.
 Figure: Relation between Kafka producers, topics, partitions, consumers and consumer groups.
Figure: Relation between Kafka producers, topics, partitions, consumers and consumer groups.
Apache Spark and Apache Flink
There are several open-source and commercial tools to simplify and optimize real-time data processing, such as Apache Spark, Apache Flink, Apache Storm, Apache Samza or Apama. Considering the current popularity of Spark and Flink-based solutions and respective stream processing characteristics, these are the tools that will be used in this example. Nevertheless, since the source code is available on GitHub, it is straightforward to add additional consumers using one of the aforementioned tools.
Apache Spark is an open-source platform for distributed batch and stream processing, providing features for advanced analytics with high speed and availability. After its first release in 2014, it has been adopted by dozens of companies (e.g., Yahoo!, Nokia and IBM) to process terabytes of data. On the other hand, Apache Flink is an open-source framework for distributed stream data processing, mostly focused on providing low latency and high fault tolerance data processing. It started from a fork of the Stratosphere distributed execution engine and it was first released in 2015. It has been used by several companies (e.g., Ebay, Huawei and Zalando) to process data in real-time.
Several blog posts already compare Spark and Flink features, functionality, latency and community. The blog posts from Chandan Prakash, Justin Ellingwood and Ivan Mushketyk present an interesting analysis, highlighting when one solution might provide added value in comparison with the other. In terms of functionality, the main difference is related with the actual streaming processing support and implementation. In summary, there are two types of stream processing:
- Native streaming (Flink): data records are processed as soon as they arrive, without waiting a specific amount of time for other records;
- Micro-batching (Spark): data records are grouped into small batches and processed together with some seconds of delay.
Considering this design difference, if the goal is to react as soon as data is delivered to the back-end infrastructure and every second counts, such behaviour might make a difference. Nonetheless, for most use cases a few seconds of delay is not significantly relevant for business goals.
Kafka Server
Before putting our hands on code, we need to have a Kafka server running, in order to develop and test our code. The following Docker Compose YML file is provided to run Zookeeper, Kafka and Kafka Manager:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
version: '3.6'
networks:
bridge:
driver: bridge
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
environment:
ZOOKEEPER_CLIENT_PORT: 32181
ZOOKEEPER_TICK_TIME: 2000
networks:
bridge:
aliases:
- zookeeper
kafka:
image: wurstmeister/kafka:latest
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ADVERTISED_HOST_NAME: 0.0.0.0
KAFKA_ZOOKEEPER_CONNECT: zookeeper:32181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
JMX_PORT: 9999
networks:
bridge:
aliases:
- kafka
kafka-manager:
image: sheepkiller/kafka-manager:latest
environment:
ZK_HOSTS: "zookeeper:32181"
ports:
- 9000:9000
networks:
- bridge
Code: docker-compose.yml file for running Zookeeper, Kafka and Kafka Manager.
Kafka Manager is a web-based tool to manage and monitor Kafka configurations, namely clusters, topics, partitions, among others. Such tool will be used to monitor Kafka usage and messages processing rate. A bridge network is also included in the compose file, which will be created to enable communication between the three services, taking advantage of the aliases announced on the network to access each service (“zookeeper” and “kafka”). That way, connection strings provided on environment variables have only the network alias and not the specific IPs, which might vary from deployment to deployment.
To start the Kafka and Kafka Manager services, we use the docker-compose tool passing the -d argument to detach and run the containers in the background:
1
docker-compose up -d
Such execution will provide detailed feedback regarding the success of creating and running each container and network:
1
2
3
4
Creating network "kafka-spark-flink-example_bridge" with driver "bridge"
Creating kafka-spark-flink-example_kafka-manager_1 ... done
Creating kafka-spark-flink-example_zookeeper_1 ... done
Creating kafka-spark-flink-example_kafka_1 ... done
After starting the containers, visit http://localhost:9000 to access the Kafka Manager, which should be similar to the one presented in the figure below:
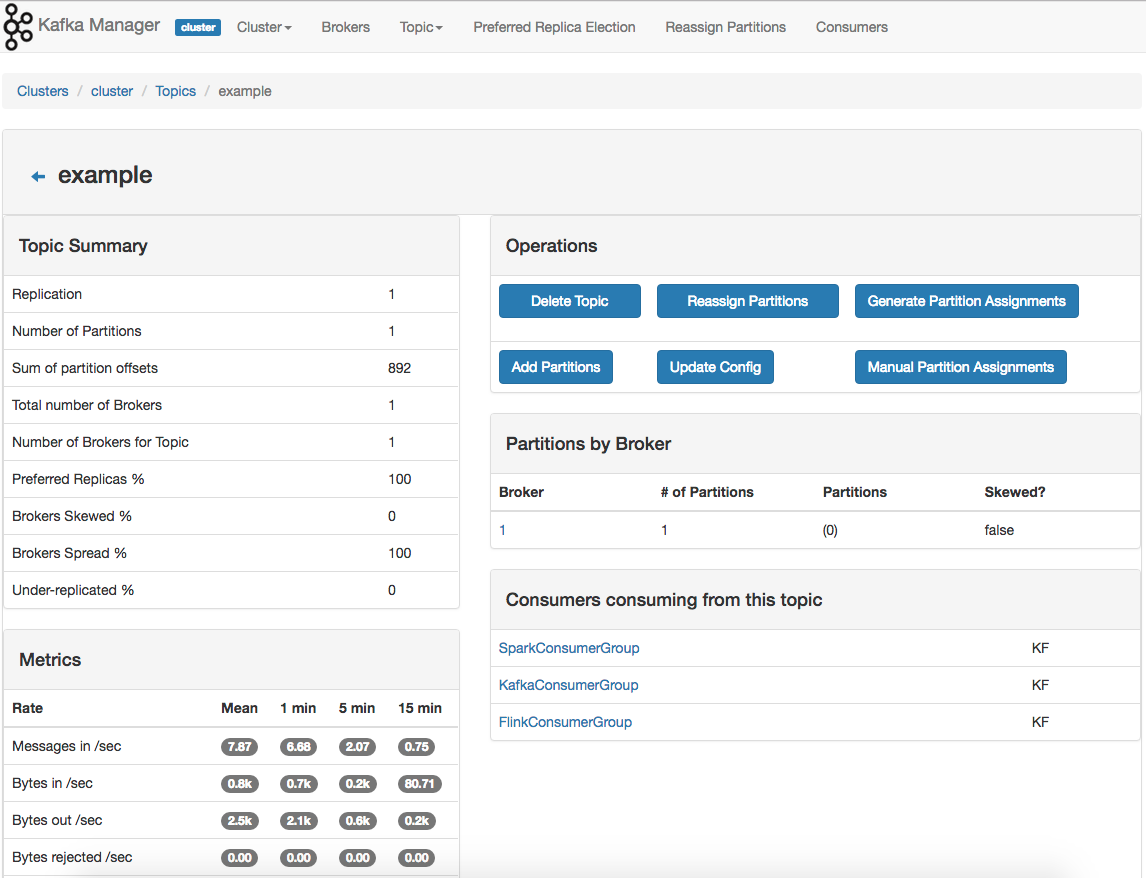 Figure: Kafka Manager interface to manage a topic and get operation feedback.
Figure: Kafka Manager interface to manage a topic and get operation feedback.
Now that Kafka is running, we are able to start developing and testing the code as soon as we develop it, sending messages and check if they are properly delivered. A single project will be created for the producer and the several consumers, varying the execution goal with environment variables. In fact, all configurations will be provided as environment variables, which simplifies the configuration process when executing Docker containers.
Configurations
The following configurations are required:
- “EXAMPLE_KAFKA_SERVER”: Kafka server connection string to send and receive messages;
- “EXAMPLE_KAFKA_TOPIC”: name of the Kafka topic to send and receive messages;
- “EXAMPLE_ZOOKEEPER_SERVER”: Zookeeper server connection string to create Kafka topic.
Such configurations will be loaded from environment variables using the Commons class, which assumes default values if no environment variables are defined.
1
2
3
4
5
6
7
8
public class Commons {
public final static String EXAMPLE_KAFKA_TOPIC = System.getenv("EXAMPLE_KAFKA_TOPIC") != null ?
System.getenv("EXAMPLE_KAFKA_TOPIC") : "example";
public final static String EXAMPLE_KAFKA_SERVER = System.getenv("EXAMPLE_KAFKA_SERVER") != null ?
System.getenv("EXAMPLE_KAFKA_SERVER") : "localhost:9092";
public final static String EXAMPLE_ZOOKEEPER_SERVER = System.getenv("EXAMPLE_ZOOKEEPER_SERVER") != null ?
System.getenv("EXAMPLE_ZOOKEEPER_SERVER") : "localhost:32181";
}
Code: Commons class to load project configurations from environment variables.
Topic
In this example each consumer has its specific group associated, which means that all messages will be delivered to all consumers. Since it is not allowed to have multiple consumers reading messages from the same partition, running multiple containers for the same consumer and consumer group will result in only one consumer receiving the messages. For instance, if we run 3 containers for the Kafka consumer, only one of them will receive the messages.
 Figure: Illustration of the topic partition and relation with consumer groups and respective consumers.
Figure: Illustration of the topic partition and relation with consumer groups and respective consumers.
In order to create the Kafka topic, the Zookeeper Client Java dependency is needed and should be added to the Maven POM file:
1
2
3
4
5
6
<!-- Zookeeper -->
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.10</version>
</dependency>
Code: Maven dependency to create a Kafka topic using the Zookeeper client.
The following code snippet implements the logic to create the Kafka topic if it does not exist. To achieve that, the Zookeeper client is used to establish a connection with the Zookeeper server, and afterwards the topic is created with only one partition and one replica.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
private static void createTopic() {
int sessionTimeoutMs = 10 * 1000;
int connectionTimeoutMs = 8 * 1000;
// Create Zookeeper Client
ZkClient zkClient = new ZkClient(
Commons.EXAMPLE_ZOOKEEPER_SERVER,
sessionTimeoutMs,
connectionTimeoutMs,
ZKStringSerializer$.MODULE$);
// Create Zookeeper Utils to perform management tasks
boolean isSecureKafkaCluster = false;
ZkUtils zkUtils = new ZkUtils(zkClient, new ZkConnection(Commons.EXAMPLE_ZOOKEEPER_SERVER), isSecureKafkaCluster);
// Create topic if it does not exist
int partitions = 1;
int replication = 1;
Properties topicConfig = new Properties();
if (!AdminUtils.topicExists(zkUtils, Commons.EXAMPLE_KAFKA_TOPIC)) {
AdminUtils.createTopic(zkUtils, Commons.EXAMPLE_KAFKA_TOPIC, partitions, replication, topicConfig, RackAwareMode.Safe$.MODULE$);
logger.info("Topic {} created.", Commons.EXAMPLE_KAFKA_TOPIC);
} else {
logger.info("Topic {} already exists.", Commons.EXAMPLE_KAFKA_TOPIC);
}
zkClient.close();
}
Code: Connect to Zookeeper and create the Kafka topic if it does not exist yet.
Producer
Now that the topic is created, we are able to create the producer to send messages to it. To accomplish that, the Kafka Clients dependency is required in the Maven POM file:
1
2
3
4
5
6
<!-- Kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.1.0</version>
</dependency>
Code: Maven dependency to create a Kafka Producer.
To create the Kafka Producer, four different configurations are required:
- Kafka Server: host name and port of Kafka server (e.g., “localhost:9092”)
- Producer identifier: unique identifier of the Kafka client (e.g., “KafkaProducerExample”);
- Key and Value Serializers: serializers allow defining how objects are translated to and from the byte-stream format used by Kafka. In this example, since both key and values are
Strings, theStringSerializerclass already provided by Kafka can be used.
The createProducer method provides a Kafka Producer instance properly configured with the previously mentioned properties:
1
2
3
4
5
6
7
8
private static Producer<String, String> createProducer() {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, Commons.EXAMPLE_KAFKA_SERVER);
props.put(ProducerConfig.CLIENT_ID_CONFIG, "KafkaProducerExample");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
return new KafkaProducer<>(props);
}
Code: Create a Kafka Producer.
To finish the Producer logic, we need to continuously send words to Kafka. The following code snippet implements that logic, sending a random word from the words array every EXAMPLE_PRODUCER_INTERVAL milliseconds (default value is 100ms). The code snippet is properly commented to make it self-explanatory.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
public static void main(final String... args) {
// Create topic
createTopic();
// Create array of words
String[] words = new String[]{"one", "two", "three", "four", "five", "six", "seven", "eight", "nine", "ten"};
// Create random
Random ran = new Random(System.currentTimeMillis());
// Create producer
final Producer<String, String> producer = createProducer();
// Get time interval to send words
int EXAMPLE_PRODUCER_INTERVAL = System.getenv("EXAMPLE_PRODUCER_INTERVAL") != null ?
Integer.parseInt(System.getenv("EXAMPLE_PRODUCER_INTERVAL")) : 100;
try {
while (true) {
// Get random word and unique identifier
String word = words[ran.nextInt(words.length)];
String uuid = UUID.randomUUID().toString();
// Build record to send
ProducerRecord<String, String> record = new ProducerRecord<>(Commons.EXAMPLE_KAFKA_TOPIC, uuid, word);
// Send record to producer
RecordMetadata metadata = producer.send(record).get();
// Log record sent
logger.info("Sent ({}, {}) to topic {} @ {}.", uuid, word, Commons.EXAMPLE_KAFKA_TOPIC, metadata.timestamp());
// Wait to send next word
Thread.sleep(EXAMPLE_PRODUCER_INTERVAL);
}
} catch (InterruptedException | ExecutionException e) {
logger.error("An error occurred.", e);
} finally {
producer.flush();
producer.close();
}
}
Code: Send a random word to Kafka every 100ms (default value).
Consumers
Now that we are able to send words to a specific Kafka topic, it is time to develop the consumers that will process the messages and count word occurrences.
Kafka Consumer
Similar to the producer, the following properties are required to create the Kafka consumer:
- Kafka Server: host name and port of Kafka server (e.g., “localhost:9092”)
- Consumer Group Identifier: unique identifier of the consumer group (e.g., “KafkaConsumerGroup”);
- Key and Value Serializers: since both key and values are
Strings, theStringSerializerclass is be used.
After creating the consumer, we need to subscribe to the EXAMPLE_KAFKA_TOPIC topic, in order to receive the messages that are sent to it by the producer:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
private static Consumer<String, String> createConsumer() {
// Create properties
final Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, Commons.EXAMPLE_KAFKA_SERVER);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "KafkaConsumerGroup");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// Create the consumer using properties
final Consumer<String, String> consumer = new KafkaConsumer(props);
// Subscribe to the topic.
consumer.subscribe(Collections.singletonList(Commons.EXAMPLE_KAFKA_TOPIC));
return consumer;
}
Code: Create Kafka consumer subscribing to topic.
To continuously collect the records sent to the topic, we can take advantage of the poll method provided in the consumer, polling a specific number of records from the topic. After that, we can process each record and count the number of word occurrences using a ConcurrentHashMap.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public static void main(final String... args) {
// Counters map
ConcurrentMap<String, Integer> counters = new ConcurrentHashMap<>();
// Create consumer
final Consumer<String, String> consumer = createConsumer();
while (true) {
// Get records
final ConsumerRecords<String, String> consumerRecords = consumer.poll(1000);
consumerRecords.forEach(record -> {
// Get word
String word = record.value();
// Update word occurrences
int count = counters.containsKey(word) ? counters.get(word) : 0;
counters.put(word, ++count);
// Log word number of occurrences
logger.info("({}, {})", word, count);
});
consumer.commitAsync();
}
}
Code: Polling 1000 records from the Kafka topic and count word occurrences.
Spark Stream Consumer
To create the Spark Consumer, the following Java dependencies are required and should be added to the POM file. Special attention is required to Scala versions of dependencies (last version number after the underscore on artifactId), making sure the project and dependencies use the same scala version (in this case 2.11), otherwise nothing will work properly with a huge amount of exceptions of missing classes.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<!--Spark-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.module</groupId>
<artifactId>jackson-module-scala_2.11</artifactId>
<version>2.9.5</version>
</dependency>
Code: Maven dependencies to create a Spark Consumer.
Since spark performs micro-batching for stream processing, a temporal batch of 5 seconds is defined, which means that the words received in the last 5 seconds are processed together in a single batch. To process the input streams of words, the MapReduce programming model is used, which has two different processing stages:
- Map: filter and sort input data converting it to tuples (key/value pairs);
- Reduce: processes the tuples from the map method and combines them into a smaller set of tuples considering a specific goal.
In this specific WordCount example, the following logic is followed:
- Get input stream of words for the last 5 seconds;
- Map words into tuples <word, occurrence> (e.g., “eight, 1”);
- Reduce tuples by word summing the occurrences (e.g., “eight, 10”);
- Print reduced set of tuples with words and total number of occurrences.
The following code snippet implements the previously mentioned algorithm, taking advantage of the Spark JavaDStream and JavaPairDStream classes for Streams and MapReduce operations.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
public static void main(final String... args) {
// Configure Spark to connect to Kafka running on local machine
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, Commons.EXAMPLE_KAFKA_SERVER);
kafkaParams.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
kafkaParams.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
kafkaParams.put(ConsumerConfig.GROUP_ID_CONFIG, "SparkConsumerGroup");
//Configure Spark to listen messages in topic test
Collection<String> topics = Arrays.asList(Commons.EXAMPLE_KAFKA_TOPIC);
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkConsumerApplication");
//Read messages in batch of 5 seconds
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(5));
// Start reading messages from Kafka and get DStream
final JavaInputDStream<ConsumerRecord<String, String>> stream =
KafkaUtils.createDirectStream(jssc, LocationStrategies.PreferConsistent(),
ConsumerStrategies.Subscribe(topics, kafkaParams));
// Read value of each message from Kafka and return it
JavaDStream<String> lines = stream.map((Function<ConsumerRecord<String, String>, String>) kafkaRecord -> kafkaRecord.value());
// Break every message into words and return list of words
JavaDStream<String> words = lines.flatMap((FlatMapFunction<String, String>) line -> Arrays.asList(line.split(" ")).iterator());
// Take every word and return Tuple with (word,1)
JavaPairDStream<String, Integer> wordMap = words.mapToPair((PairFunction<String, String, Integer>) word -> new Tuple2<>(word, 1));
// Count occurrence of each word
JavaPairDStream<String, Integer> wordCount = wordMap.reduceByKey((Function2<Integer, Integer, Integer>) (first, second) -> first + second);
//Print the word count
wordCount.print();
jssc.start();
try {
jssc.awaitTermination();
} catch (InterruptedException e) {
logger.error("An error occurred.", e);
}
}
Code: Spark stream consumer to count words occurrences from last 5s.
Flink Stream Consumer
To build the Flink consumer, the following dependencies are required in the Maven POM file:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
<!--Flink-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.4.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.4.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>1.4.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_2.11</artifactId>
<version>1.4.2</version>
</dependency>
Code: Maven dependencies to create a Flink Consumer.
The Flink consumer also takes advantage of the MapReduce programming model, following the same strategy previously presented for the Spark consumer. In this case, the Flink DataStream class is used, which provides cleaner and easier to understand source code, as we can see below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
public static void main(final String... args) {
// Create execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Properties
final Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, Commons.EXAMPLE_KAFKA_SERVER);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "FlinkConsumerGroup");
DataStream<String> messageStream = env.addSource(new FlinkKafkaConsumer010<>(Commons.EXAMPLE_KAFKA_TOPIC, new SimpleStringSchema(), props));
// Split up the lines in pairs (2-tuples) containing: (word,1)
messageStream.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.keyBy(0)
.sum(1)
.print();
try {
env.execute();
} catch (Exception e) {
logger.error("An error occurred.", e);
}
}
public static final class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
Code: Setup Flink to continuously consume messages and count and print occurrences per word.
Main
To get everything together, the Main application is created to run a specific application depending on the execution goal. The environment variable EXAMPLE_GOAL is used to get the goal of the program, i.e., to run a producer or a consumer with Kafka, Spark or Flink. By doing this we can have a single Docker Image to run the 4 different goals, which might vary with the provided environment variable.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public static void main(final String... args) {
String EXAMPLE_GOAL = System.getenv("EXAMPLE_GOAL") != null ?
System.getenv("EXAMPLE_GOAL") : "producer";
logger.info("Kafka Topic: {}", Commons.EXAMPLE_KAFKA_TOPIC);
logger.info("Kafka Server: {}", Commons.EXAMPLE_KAFKA_SERVER);
logger.info("Zookeeper Server: {}", Commons.EXAMPLE_ZOOKEEPER_SERVER);
logger.info("GOAL: {}", EXAMPLE_GOAL);
switch (EXAMPLE_GOAL.toLowerCase()) {
case "producer":
KafkaProducerExample.main();
break;
case "consumer.kafka":
KafkaConsumerExample.main();
break;
case "consumer.spark":
KafkaSparkConsumerExample.main();
break;
case "consumer.flink":
KafkaFlinkConsumerExample.main();
break;
default:
logger.error("No valid goal to run.");
break;
}
}
Code: Main program to select which program to run.
Build package
Finally, in order to build fat JAR file with all dependencies included, the Maven Shade Plugin was used. Tried doing this using the Maven Assembly Plugin but had problems to gather all Flink dependencies in the fat JAR.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>jar-with-dependencies</shadedClassifierName>
<artifactSet>
<includes>
<include>*:*</include>
</includes>
</artifactSet>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<manifestEntries>
<Main-Class>org.davidcampos.kafka.cli.Main</Main-Class>
</manifestEntries>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
To build the fat JAR, please run mvn clean package in the project folder, which stores the resulting JAR kafka-spark-flink-example-1.0-SNAPSHOT-jar-with-dependencies.jar in the target folder.
Docker Image
To build the Docker Image for the producer and consumers, the following Dockerfile was built using the OpenJDK image as baseline:
1
2
3
4
5
6
7
8
9
10
11
12
13
FROM openjdk:8u151-jdk-alpine3.7
MAINTAINER David Campos (david.marques.campos@gmail.com)
# Install Bash
RUN apk add --no-cache bash
# Copy resources
WORKDIR /
COPY wait-for-it.sh wait-for-it.sh
COPY target/kafka-spark-flink-example-1.0-SNAPSHOT-jar-with-dependencies.jar kafka-spark-flink-example.jar
# Wait for Zookeeper and Kafka to be available and run application
CMD ./wait-for-it.sh -s -t 30 $EXAMPLE_ZOOKEEPER_SERVER -- ./wait-for-it.sh -s -t 30 $EXAMPLE_KAFKA_SERVER -- java -Xmx512m -jar kafka-spark-flink-example.jar
Code: Dockerfile for building Docker image.
wait-for-it.sh is used to check if a specific host and port is available and only run the provided command when connectivity is established. wait-for-it.sh was developed by Giles Hall and is available at https://github.com/vishnubob/wait-for-it. In this example, producer and consumers should only be started when kafka is successfully running with connectivity available.
To build the docker image, run the following command in the project folder:
1
docker build -t kafka-spark-flink-example .
After the build process, check on docker images if it is available, by running the command docker images. If the image is available, the output should me similar to the following:
1
2
REPOSITORY TAG IMAGE ID CREATED SIZE
kafka-spark-flink-example latest 3bd70969dacd 4 days ago 253MB
Docker compose
To create the containers running the Producer and the three Consumers, the previous Docker Compose YML file should be extended, adding the configurations for the Kafka Producer, Kafka Consumer, Spark Consumer and Flink Consumer. The environment variables to specify the Kafka Topic, Kafka Server, Zookeeper Server, Execution goal and Messages cadence are also provided.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
kafka-producer:
image: kafka-spark-flink-example
depends_on:
- kafka
environment:
EXAMPLE_GOAL: "producer"
EXAMPLE_KAFKA_TOPIC: "example"
EXAMPLE_KAFKA_SERVER: "kafka:9092"
EXAMPLE_ZOOKEEPER_SERVER: "zookeeper:32181"
EXAMPLE_PRODUCER_INTERVAL: 100
networks:
- bridge
kafka-consumer-kafka:
image: kafka-spark-flink-example
depends_on:
- kafka-producer
environment:
EXAMPLE_GOAL: "consumer.kafka"
EXAMPLE_KAFKA_TOPIC: "example"
EXAMPLE_KAFKA_SERVER: "kafka:9092"
EXAMPLE_ZOOKEEPER_SERVER: "zookeeper:32181"
networks:
- bridge
kafka-consumer-spark:
image: kafka-spark-flink-example
depends_on:
- kafka-producer
ports:
- 4040:4040
environment:
EXAMPLE_GOAL: "consumer.spark"
EXAMPLE_KAFKA_TOPIC: "example"
EXAMPLE_KAFKA_SERVER: "kafka:9092"
EXAMPLE_ZOOKEEPER_SERVER: "zookeeper:32181"
networks:
- bridge
kafka-consumer-flink:
image: kafka-spark-flink-example
depends_on:
- kafka-producer
environment:
EXAMPLE_GOAL: "consumer.flink"
EXAMPLE_KAFKA_TOPIC: "example"
EXAMPLE_KAFKA_SERVER: "kafka:9092"
EXAMPLE_ZOOKEEPER_SERVER: "zookeeper:32181"
networks:
- bridge
Run
Now that everything is in place, it is time to start the containers using the docker-compose tool, passing the -d argument to detach and run the containers in the background:
1
docker-compose up -d
Such execution will provide detailed feedback regarding the success of creating and running each container and network:
1
2
3
4
5
6
7
8
Creating network "kafka-spark-flink-example_bridge" with driver "bridge"
Creating kafka-spark-flink-example_kafka-manager_1 ... done
Creating kafka-spark-flink-example_zookeeper_1 ... done
Creating kafka-spark-flink-example_kafka_1 ... done
Creating kafka-spark-flink-example_kafka-producer_1 ... done
Creating kafka-spark-flink-example_kafka-consumer-flink_1 ... done
Creating kafka-spark-flink-example_kafka-consumer-kafka_1 ... done
Creating kafka-spark-flink-example_kafka-consumer-spark_1 ... done
To stop and remove all containers, please take advantage of the down option of the docker-compose tool:
1
docker-compose down
Detailed feedback about stopping and destroying each container and network is also provided:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Stopping kafka-spark-flink-example_kafka-consumer-flink_1 ... done
Stopping kafka-spark-flink-example_kafka-consumer-kafka_1 ... done
Stopping kafka-spark-flink-example_kafka-consumer-spark_1 ... done
Stopping kafka-spark-flink-example_kafka_1 ... done
Stopping kafka-spark-flink-example_zookeeper_1 ... done
Stopping kafka-spark-flink-example_kafka-manager_1 ... done
Removing kafka-spark-flink-example_kafka-consumer-flink_1 ... done
Removing kafka-spark-flink-example_kafka-consumer-kafka_1 ... done
Removing kafka-spark-flink-example_kafka-consumer-spark_1 ... done
Removing kafka-spark-flink-example_kafka-producer_1 ... done
Removing kafka-spark-flink-example_kafka_1 ... done
Removing kafka-spark-flink-example_zookeeper_1 ... done
Removing kafka-spark-flink-example_kafka-manager_1 ... done
Removing network kafka-spark-flink-example_bridge
Validate
In order to check if everything is working properly, we can take advantage of the docker logs tool to analyse the output being generated on each container. In that context, we can check the logs of the producer and consumers to validate that data is being processed properly.
Producer
Run the following command to access producer logs:
1
docker logs kafka-spark-flink-example_kafka-producer_1 -f
Output should be similar to the following example, were each line represents a word already sent to Kafka:
1
2
3
4
5
6
7
8
9
20:43:41.355 [main] INFO org.davidcampos.kafka.producer.KafkaProducerExample - Sent (ac8f0337-bbde-4e92-8659-c847aa7b7eaf, four) to topic example @ 1525725821264.
20:43:41.468 [main] INFO org.davidcampos.kafka.producer.KafkaProducerExample - Sent (6ece8f3c-72b8-40a0-a37f-398d6cb9ee76, six) to topic example @ 1525725821455.
20:43:41.590 [main] INFO org.davidcampos.kafka.producer.KafkaProducerExample - Sent (9eba2ad9-5926-4eac-b3b4-1bde27209d77, two) to topic example @ 1525725821569.
20:43:41.768 [main] INFO org.davidcampos.kafka.producer.KafkaProducerExample - Sent (0eb0c80b-760e-47f3-8a73-f86868d83ff4, two) to topic example @ 1525725821694.
20:43:41.876 [main] INFO org.davidcampos.kafka.producer.KafkaProducerExample - Sent (ca247271-07b4-4bb9-834a-27ec5168e9cf, two) to topic example @ 1525725821869.
20:43:41.985 [main] INFO org.davidcampos.kafka.producer.KafkaProducerExample - Sent (ab715932-0b28-46cb-9c89-b6965e34619c, eight) to topic example @ 1525725821977.
20:43:42.103 [main] INFO org.davidcampos.kafka.producer.KafkaProducerExample - Sent (74b60cc9-0849-4468-8125-fd6b368e5e66, three) to topic example @ 1525725822087.
20:43:42.218 [main] INFO org.davidcampos.kafka.producer.KafkaProducerExample - Sent (51d80cf5-d601-476b-9eb6-33f44ca94716, ten) to topic example @ 1525725822204.
20:43:42.329 [main] INFO org.davidcampos.kafka.producer.KafkaProducerExample - Sent (0a9a20b1-06c9-4103-ac3d-66bc48397936, eight) to topic example @ 1525725822318.
Kafka consumer
Run the following command to review Kafka consumer logs:
1
docker logs kafka-spark-flink-example_kafka-consumer-kafka_1 -f
For every word received the respective total number of occurrences is displayed, as we can see below:
1
2
3
4
5
6
7
8
9
10
11
14:14:43.463 [main] INFO org.davidcampos.kafka.consumer.KafkaConsumerExample - (five, 27)
14:14:43.581 [main] INFO org.davidcampos.kafka.consumer.KafkaConsumerExample - (three, 15)
14:14:43.709 [main] INFO org.davidcampos.kafka.consumer.KafkaConsumerExample - (seven, 35)
14:14:43.822 [main] INFO org.davidcampos.kafka.consumer.KafkaConsumerExample - (seven, 36)
14:14:43.931 [main] INFO org.davidcampos.kafka.consumer.KafkaConsumerExample - (four, 19)
14:14:44.043 [main] INFO org.davidcampos.kafka.consumer.KafkaConsumerExample - (four, 20)
14:14:44.157 [main] INFO org.davidcampos.kafka.consumer.KafkaConsumerExample - (five, 28)
14:14:44.273 [main] INFO org.davidcampos.kafka.consumer.KafkaConsumerExample - (seven, 37)
14:14:44.386 [main] INFO org.davidcampos.kafka.consumer.KafkaConsumerExample - (five, 29)
14:14:44.493 [main] INFO org.davidcampos.kafka.consumer.KafkaConsumerExample - (nine, 21)
14:14:44.604 [main] INFO org.davidcampos.kafka.consumer.KafkaConsumerExample - (one, 12)
Spark consumer
To check Spark consumer logs please run:
1
docker logs kafka-spark-flink-example_kafka-consumer-spark_1 -f
Every 5s, Spark will output the number of occurrences for each word for that specific period of time, similar to:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
-------------------------------------------
Time: 1541082310000 ms
-------------------------------------------
(two,4)
(one,7)
(nine,3)
(six,6)
(three,9)
(five,2)
(four,3)
(seven,4)
(eight,5)
(ten,2)
-------------------------------------------
Time: 1541082315000 ms
-------------------------------------------
(two,4)
(one,8)
(nine,3)
(six,9)
(three,7)
(five,1)
(four,4)
(seven,3)
(ten,7)
Additionally, you can also check the Spark UI interface available at http://localhost:4040. Such web-based tool provides relevant information for monitoring and instrumentation, with detailed information about the jobs executed, elapsed time, memory usage, among others.
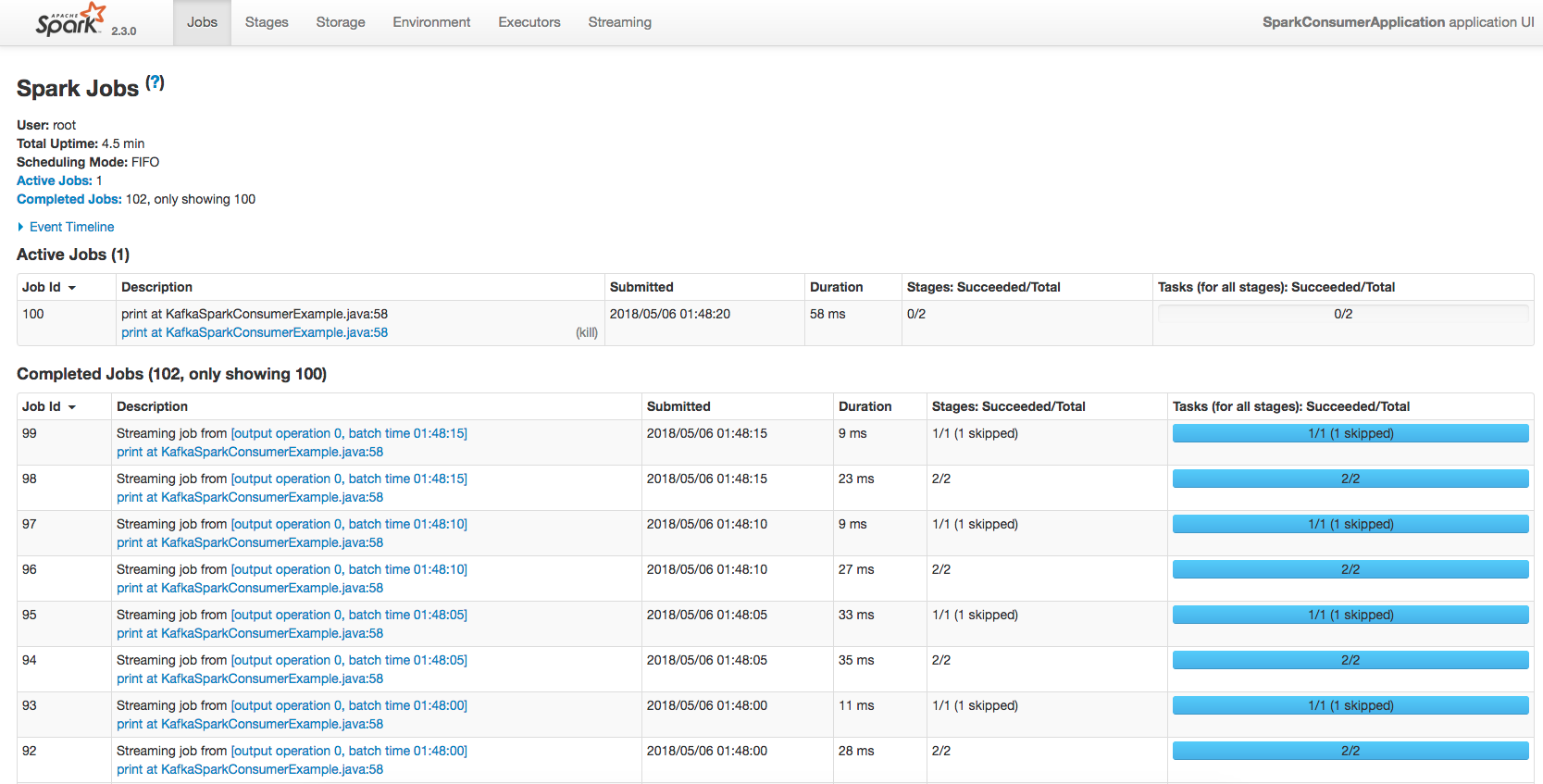 Figure: Spark interface to check active jobs and respective status.
Figure: Spark interface to check active jobs and respective status.
Flink consumer
Finally, we can check Flink logs by executing:
1
docker logs kafka-spark-flink-example_kafka-consumer-flink_1 -f
Since Flink is a timeseries-based approach it reacts to every message received. As a result, for every word received the respective total number of occurrences is displayed, as we can see below:
1
2
3
4
5
6
7
8
9
1> (ten,85)
4> (nine,104)
1> (ten,86)
4> (five,91)
4> (one,94)
4> (six,90)
1> (three,89)
4> (six,91)
4> (five,92)
We did it!
It is done and working properly! The producer is sending the messages to Kafka and all consumers are receiving and processing the messages, showing the number of occurrences for each word.

Scale it up
Just one more thing. What about increasing the number of messages being sent? As a first approach, we can change the time interval between requests. By default, this value is set to 100ms, which means that a message is sent every 100ms. To change this behaviour, set the EXAMPLE_PRODUCER_INTERVAL environment variable to specify the producer time interval between requests to Kafka. Thus, changing the docker-compose.yml accordingly (line 10), we can send a word to Kafka every 10ms.
1
2
3
4
5
6
7
8
9
10
11
12
kafka-producer:
image: kafka-spark-flink-example
depends_on:
- kafka
environment:
EXAMPLE_GOAL: "producer"
EXAMPLE_KAFKA_TOPIC: "example"
EXAMPLE_KAFKA_SERVER: "kafka:9092"
EXAMPLE_ZOOKEEPER_SERVER: "zookeeper:32181"
EXAMPLE_PRODUCER_INTERVAL: 10
networks:
- bridge
In order to scale the number of messages even further, two different options can be considered:
- Add multi-thread support to producer in order to send multiple messages at the same time;
- Have multiple producer containers sending multiple messages at the same time.
Considering the example context, it is more straightforward to take advantage of Docker to run multiple containers of the producer service. In a real world-application, a less resource intensive approach might be considered. Thus, in order to change the number of replicas for the producer service, we can take advantage of the --scale argument of docker-compose up. It works by specifying the number of containers for the service name, such as --scale <service_name>=<number_of_containers>. In the next example we request three containers for the kafka-producer service:
1
docker-compose up -d --scale kafka-producer=3
When you do this, in the output you can check Docker starting three different containers for the producer service:
1
2
3
Creating kafka-spark-flink-example_kafka-producer_1 ... done
Creating kafka-spark-flink-example_kafka-producer_2 ... done
Creating kafka-spark-flink-example_kafka-producer_3 ... done
After a while, instead of receiving ~50 messages every 5s, we receive almost 1000 messages per 5s, which represents a 20x increase with just some small changes. The Spark consumer logs confirm the high number of words received in 5s:
1
2
3
4
5
6
7
8
9
10
11
12
13
-------------------------------------------
Time: 1525543330000 ms
-------------------------------------------
(two,92)
(one,96)
(nine,83)
(six,113)
(three,88)
(five,82)
(four,100)
(seven,91)
(eight,106)
(ten,88)
Besides this simple exercise to scale up the example, keep in mind that with only three servers, Jay Kreps was able to write 2 million messages per second into Kafka and read almost 1 million records from Kafka in a single thread. Such example reflects the scalability and processing power of Kafka. For a more detailed analysis, you can access this Kafka benchmark in the LinkedIn Engineering Blog.
Conclusion
I hope this example helps to understand how Kafka can be used as a communication broker between producers and consumers with different purposes. Nonetheless, keep in mind that using Kafka in large-scale applications with hundreds of thousands of producers and consumers requires high level of expertise for configuring and maintaining the service running with expected availability, performance, robustness and fault tolerance behaviour. Several companies already provide enterprise Kafka services for large-scale applications, such as Clonfluent, Amazon, Azure and Cloudera. Not saying it is cheap, but it is definitely an option if such expertise is not in the company portfolio.
Please remember that your comments, suggestions and contributions are more than welcome.
Happy Kafking and Streaming! ![]()
Comments